

һ��ǰ��
оƬ��ُ�W(w��ng)��ע�����χ���(n��i)���ڙ�(qu��n)IC�����̬F(xi��n)؛�YԴ��оƬ��挍�r��ԃ���ИI(y��)�r���������ُ����ICоƬ������(n��i)���I(y��)оƬ��ُƽ�_��
�˹����ܣ��˹����ܣ�AI���V����(y��ng)���ڸ��N��(y��ng)�á�Ӳ�����㷨�͔�(sh��)��(j��)���˹����ܵ�����֧�Σ�����Ӳ����ָ�\�� AI �㷨оƬ������(y��ng)��Ӌ��ƽ�_������ʹ�È���Խ��Խ�࣬��Ҫ̎���Ĕ�(sh��)��(j��)��Խ��Խ���˂�������ҲԽ��Խ�ߣ��@ʹ��AIӲ��ƽ�_�ϱ����Ч���\���㷨��Ŀǰ��Ҫ����Ӳ���� GPU ��(j��ng)�W(w��ng)�j(lu��)����Ӌ�㣬߀�� FPGA �� ASIC Ҳ��δ����܊ͻ��ĝ�����
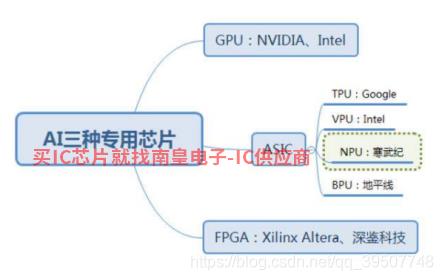
GPU�����Q��D��̎���������@�������K CPU ��Ƶأ���ֻ��һ�N���T���D�������̎������GPU �ڸ��cӋ��Ͳ���Ӌ���У������ṩ��(sh��)ʮ��������(sh��)�ٱ� CPU ���ܡ����ڑ�(y��ng)������ȌW(xu��)��(x��)�㷨�r�������������ԣ�
����Ӌ�マ(y��u)���ڑ�(y��ng)���^���в��ܳ�ְl(f��)�]
Ӳ���Y(ji��)��(g��u)�̶����ɾ���
������ȌW(xu��)��(x��)�㷨��Ч���h(yu��n)���� ASIC �� FPGA��
FPGA�Ñ����Ը���(j��)�Լ�����Ҫ�؏�(f��)���̣��Q��F(xi��n)���ɾ����T��С� GPU��CPU ���֮�£��ߡ��ܺĵ͡���Ӳ�����̵����c��FPGA ��GPU �����^�ͣ������^�� ASIC �_�l(f��)�r�g�̣��ɱ��͡�FPGAҲ�����N����:
������Ԫ��Ӌ���������ޣ�
��Ҫ����ٶȺ��ģ�
FPGA ���^�F��
ASIC��Application Specific Integrated Circuit���Ǟ�����Ŀ���O(sh��)Ӌ�ļ����·���������¾��̣�Ч�ʸߣ����ĵͣ����r���F����������F(xi��n)���F(xi��n)TPU��NPU��VPU��BPU���N�����ۻ����y��оƬ�����|(zh��)�϶�����ASIC��ASIC��ͬ�� GPU �� FPGA ���Ƶ��`���� ASIC һ��������ɣ��Ͳ��ܸ�׃�����Գ�ʼ�ɱ��ߣ��_�l(f��)�����L���M(j��n)���T���ߡ�Ŀǰ�ֶ����е� AI �㷨Ҳ���LоƬ�аl(f��)�ľ��^���� Google �� TPU���c��(j��ng)�W(w��ng)�j(lu��)���P(gu��n)���㷨�����m�ã�ASIC ��(y��u)�����ܺ��� GPU �� FPGA��TPU1 �ǂ��y(t��ng) GPU ���ܵ� 14-16 ����NPU �� GPU �� 118 ��������o(j��)�Ѱl(f��)�����⑪(y��ng)��ָ����A(y��)Ӌ ASIC ����δ�� AI оƬ�ĺ��ġ�
�C�������������ܷ��棬ASIC��(y��u)�������NӋ�㷽����ASIC�ڱ���оƬ�У�NPU���ܷdz�ͻ���������Bһ��NPU��
����NPU��B
���^NPU��Neural network Processing Unit���� ����(j��ng)�W(w��ng)�j(lu��)̎���������˼�x�������·ģ�M�����(j��ng)Ԫ��ͻ�|�Y(ji��)��(g��u)������������·ģ�������(j��ng)Ԫ�����횰�ÿ����(j��ng)Ԫ�����һ�������(sh��)������ݔ�������B����(j��ng)Ԫ��ݔ�����B����(j��ng)Ԫ��ͻ�|�Q���ġ����˱��_(d��)�ض���֪�R���Ñ�ͨ����Ҫ�{(di��o)���˹���(j��ng)�W(w��ng)�j(lu��)�е�ͻ�|ֵ���W(w��ng)�j(lu��)����?f��)�Y(ji��)��(g��u)�ȡ��@һ�^�̷Q��W(xu��)��(x��)���W(xu��)��(x��)���˹���(j��ng)�W(w��ng)�j(lu��)����ͨ�^�W(xu��)��(x��)��֪�R����Q�ض��Ć��}��
������ȌW(xu��)��(x��)�Ļ���������̎����(j��ng)Ԫ��ͻ�|�������y(t��ng)��̎����ָ�(����x86��ARM�ȣ��Ǟ����_�l(f��)һ��Ӌ�㣬��������������g(sh��)�������Ӝp�˳�����߉�������ͻ�ǣ���ͨ����Ҫ��(sh��)��������(sh��)ǧ��ָ��������(j��ng)Ԫ��̎������ȌW(xu��)��(x��)��̎��Ч�ʲ��ߡ��˕r���҂�����ҵ�һ�N�µķ�����ͻ�ƽ�(j��ng)����T���Z�����Y(ji��)��(g��u)��
�惦��̎������(j��ng)�W(w��ng)�j(lu��)����һ�w�ģ����w�F(xi��n)��ͻ�|��(qu��n)���ϡ� ���T�����Z�����Y(ji��)��(g��u)�У��惦��̎���Ƿ��_�ģ��քe�ɴ惦����Ӌ�������F(xi��n)������֮�g���ھ�IJ���ìF(xi��n)�еĻ����T����(j��ng)����Z�����Y(ji��)��(g��u)Ӌ��C(��XӢ���_(d��)86̎����GPU���\����(j��ng)�W(w��ng)�j(lu��)�r�����ɱ���ؕ��ܵ��惦��̎�����x�Y(ji��)��(g��u)�����ƣ��Ķ�Ӱ�Ч�ʡ��@Ҳ�nj��Tᘌ��˹����ܵČ��I(y��)оƬ�����y(t��ng)оƬ����һ�����샞(y��u)�ݵ�ԭ��֮һ��
NPU���ʹ������(n��i)����o(j��)��Cambricon��оƬ��IBM��TrueNorth�����Ї�����o(j��)������2016��3�£��Ї��ƌW(xu��)ԺӋ�㼼�g(sh��)�о�����Ƽ������ʯ�о�С�M����������ϵ�һ����ȌW(xu��)��(x��)̎����ָ�DianNaoYu��DianNaoYuָ�����ֱ��̎����Ҏ(gu��)ģ��(j��ng)Ԫ��ͻ�|��һ�M��(j��ng)Ԫ����ͨ�^һ��ָ��̎��������оƬ����(j��ng)Ԫ��ͻ�|��(sh��)��(j��)�Ă�ݔ�ṩһϵ������֧�֡�
��������o(j��)NPU��B
����o(j��)�Ƽ���2016��l(f��)���������ϵ�һ���K��AI��������(j��ng)�W(w��ng)�j(lu��)̎����(NPU)������o(j��)1A��(Cambricon-1A)�������֙C����ȫ�O(ji��n)�ء��ɴ����O(sh��)�䡢�o�˙C�������{�ȽK���O(sh��)������������㷨�ܺı���ȫ���^���y(t��ng)CPU��GPU���������Ӳ���ܘ�(g��u)��ܛ��֧��Caffe��Tensorflow��MXnet������AI�_�l(f��)ƽ�_���ɏV����(y��ng)����Ӌ��Cҕ�X���Z���R�e����Ȼ�Z��̎��������̎�����P(gu��n)�I�I(l��ng)��
2017�꣬����o(j��)�Ƽ��l(f��)���˵ڶ���NPU����o(j��)1�ļܘ�(g��u)H����Cambricon-1H����ԓϵ�бȵ�һ���a(ch��n)Ʒ1Aԓϵ�е���Ч������˔�(sh��)�����ɏV����(y��ng)����Ӌ��Cҕ�X���Z���R�e����Ȼ�Z��̎��������̎�����P(gu��n)�I�I(l��ng)�����У�Cambricon-1H16�汾��IP����1H2566ϵ�и����ܰ�MAC 5126λ���c�\����MAC 8λ���c�\��������1GHz�����l�£�16λ���c��(j��ng)�W(w��ng)�j(lu��)�ķ�ֵ�ٶȞ�0.5Tops��8λ���c��(j��ng)�W(w��ng)�j(lu��)�\��ķ�ֵ�ٶȞ�1Tops��Cambricon-1H8�汾IP����1H512MAC 8λ���c�\��������1GHz�����l�£�8λ���c��(j��ng)�W(w��ng)�j(lu��)�\��ķ�ֵ�ٶȞ�1Tops��Cambricon-1H8mini�汾IP����1H2566ϵ���p������MAC 8λ���c�\��������1GHz�����l�£�8λ���c��(j��ng)�W(w��ng)�j(lu��)�ķ�ֵ�ٶȞ�0.5Tops��
2018�꣬����o(j��)�Ƽ��l(f��)���˵�����IP����o(j��)1�a(ch��n)ƷM����Cambricon-1M���������ϵ�һ���_�e�7nm��ˇ���죬�ܺı�5Tops/W����ÿ�����\��5�f�|�Σ��ṩ2Tops��4Tops��8Tops�M�㲻ͬ��������ͬ���������NҎ(gu��)ģ̎������AI̎������֧�ֶ�˻�(li��n)������o(j��)1Mǰ�ɴ�̎�������m(x��)IP�a(ch��n)Ʒ����o(j��)1H/1AԽ��TracoPower������̎�����˿���֧��������CNN��RNN��SOM�M(j��n)һ��֧�ֶ�Ԫ������ȌW(xu��)��(x��)ģʽSVM��k-NN��k-Means���Q�ߘ�Ƚ�(j��ng)��C���W(xu��)��(x��)�㷨֧�ֱ�����Ӗ(x��n)����ҕ�X���Z������Ȼ�Z��̎�����N��(j��ng)��C���W(xu��)��(x��)�΄�(w��)�ṩ�`���Ч��Ӌ��ƽ�_���ɏV����(y��ng)���������֙C�����ܓP�������ܔz���^�������{���I(l��ng)��
�ġ�Cambricon-1A NPU��(y��ng)��
�@�����Ƚ�B�A�麣˼����970�֙C̎������������������ϵ�һ���˹������Ƅ�Ӌ��ƽ�_���ǘI(y��)��(n��i)��һ��������NPU��Neural Network Processing Unit���֙CоƬ����Ӳ��̎���Ԫ������970��(chu��ng)�¼���NPU��(chu��ng)���O(sh��)Ӌ�ˌ���Ӳ��̎���ԪHiAI�Ƅ�Ӌ��ܘ�(g��u)����AI�����ܶ����@��(y��u)��CPU��GPU�����^���Ă�Cortex-A73����̎����ͬAI�΄�(w��)���µĮ���(g��u)Ӌ��ܘ�(g��u)�мs 50 ����Ч�� 25 ���܃�(y��u)�ݱ����D���R�e�ٶȿ��_(d��)2000��/������ҡ���ˏ���NPU����o(j��)ʹ�õČ���Ӳ��̎���ԪCambricon-1Aϵ�е�IP��������970оƬ���ɺ���o(j��)1A̎��������������˹�����̎���Ԫ��NPU����
��������������������������������
���(qu��n)�������Ğ�CSDN���������ĵ�С�ڡ���ѭԭ��(chu��ng)����CC 4.0 BY-SA���(qu��n)�f(xi��)�h��Ո����ԭʼ��Դ朽Ӻͱ�����
ԭ��朽ӣ�https://blog.csdn.net/qq_39507748/article/details/109402395




















- �����ڸ����B�T�O(sh��)���k��̎ ������Ҫ�ĘI(y��)��(w��)��չƽ�_
- Digi-Key ȫ�ҬF(xi��n)؛�N�� u-blox ������ XPLR-IoT-1 ��
- �������Ƴ��˽�(j��ng)�J(r��n)�C��ȫ��EdgeLock������(li��n)�W(w��ng)�O(sh��)�䰲ȫ�J(r��n)�CоƬ�İ�ȫ������C
- ��벢�e��Power Integrationsʹ?f��n)�����׃������ȫ�ɿ?/a>
- �L�Ŵ惦����Q2����17nm DRAM��Ʒ
- ���������죺оƬ��ȱ���ص�׃�O(sh��)Ӌ����ُ����(y��ng)机�������P(gu��n)ϵ
- Ӣ�ؠ��c�ٶȔy���ƄӮa(ch��n)�I(y��)���ܻ��M(j��n)�̣�����(chu��ng)�Gɫδ��
- �҇� IPv6 �W(w��ng)�j(lu��)���ٹ�·ȫ�潨�ɣ����S�Ñ��_(d��)�� 6.93 �|
- �_���Ʊ�Թ�����ҕ�b�����O(sh��)Ӌ����hƷ���_���a(ch��n)Ʒ��(j��ng)��
- MolexĪĪ�˔Uչȫ��a(ch��n)��
- ��(chu��ng)�£����I(l��ng)δ��
- �c�R˹�˽������ �����i���ˆT���Ĺə�(qu��n)�~��
